DLite V2: Lightweight, Open LLMs That Can Run Anywhere
By Jacob Renn and Ian Sotnek — September 5, 2023
DLite V2: Lightweight, Open, Easily Customizable LLMs
By Jacob Renn and Ian Sotnek — September 5, 2023
Introduction
AI Squared is committed to democratizing AI so that it can be used by all. There are two key forces opposing the democratization of AI though — a tendency for high-performing models to have a huge number of parameters, making them incredibly expensive to train, tune, and deploy at scale — and nonpermissive licensing preventing many open source models from being used for commercial purposes.
Getting high performance from smaller models would greatly reduce the start-up and operational costs of building with large language models.
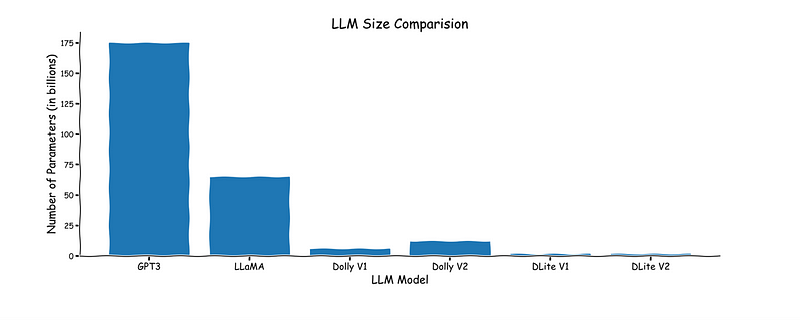
To address the size / cost aspect of this current situation, in April 2023 , we released our DLite V1 family of models, which are lightweight LLMs ranging from 124 million parameters to 1.5 billion parameters that exhibit ChatGPT-like interactivity. The small size of these models means that they can be run on almost any device, including laptop CPUs, instead of being limited to deployment on specialized, expensive cloud resources. At this point, however, we were using the Alpaca dataset to tune the model, which prevented any of the DLite v1 family from being used for commercial purposes.
We’ve since updated the DLite family with DLite V2, which also has four different models ranging from 124 million to 1.5 billion parameters. The highlight of the update was our utilization of the `databricks-dolly-15k` dataset released by Databricks. We have also uploaded this dataset to our HuggingFace page so anyone can easily use it. Because this training dataset is also licensed for commercial purposes, we are also happy to announce that all models in the DLite V2 family can also be used for commercial purposes, enabling organizations to build upon these models with no licensing constraints whatsoever.
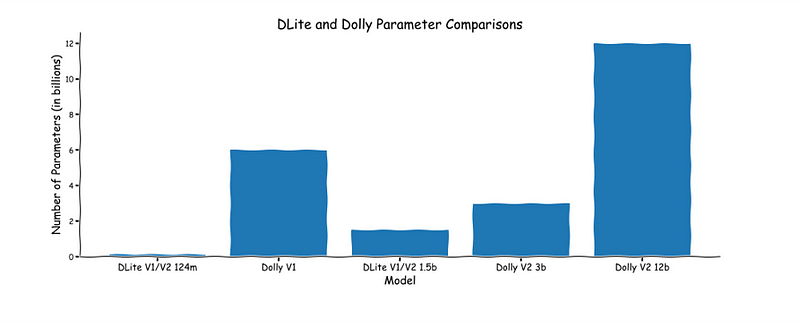
Based on GPT-2, the DLite family shows that even older, smaller models can still yield performant and, more importantly, useful chat agents.
Because our smallest DLite model is just 124 million parameters, it is extremely easy and cost-efficient to train and utilize the model. Just as with our V1 version, we trained this model on a single T4 GPU, this time with a cost of less than $10. And while DLite V2 does not achieve state-of-the-art performance, the openness of the models enables organizations to be able to fine tune this model on their own data to specialize the models for their own tasks. We believe this is an important step in the democratization of AI for all!
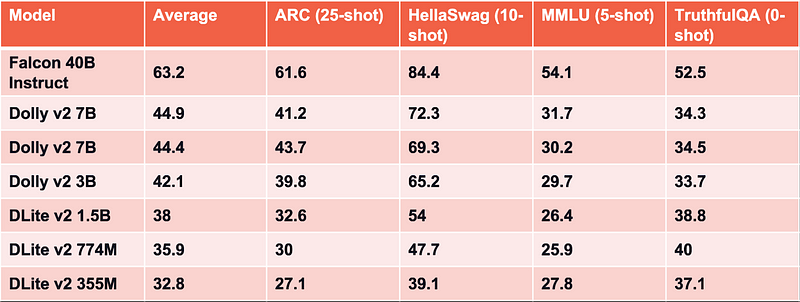
While not SOTA, the DLite family performs admirably for their size on the Huggingface Open LLM Leaderboard
At this point, we need to acknowledge the elephant in the room — or, really, the Falcons and Llamas in the room — which is that just choosing to use smaller models is not the only way to run large language models on consumer-grade hardware. There has recently been a trend towards taking larger, more state-of-the-art models and quantizing them by representing their weights and activations in fewer bits, for example by converting the representation of a model’s weights and activations from a higher precision data type like a 32-bit floating point number to a lower precision value such as a 4-bit integer. It is true that for most use cases, when comparing models based on memory footprint, quantized large LLMs outperform full-precision smaller LLMs, however:
- Large quantized LLMs can run on commodity hardware, especially if the device has a GPU and / or you’re running the model in C or C++ without any dependencies (e.g. llama.cpp), but there are still few options to run truly SOTA models in a useable manner on lightweight consumer devices such as business-class laptops. Just because you *can* run Llama-2–13B-chat-ggml-q4 on a Macbook CPU at 2.6GHz with 16Gb RAM, for more than very succinct Q&A-type interactions 3 tokens per second will all but guarantee frustrated end users.
- The costs to tune a larger model prior to quantization are quite high compared to the costs of tuning a smaller full-precision model. This difference might not be significant for enterprises, but for those of us without admin rights in our organization’s Databricks account every dollar matters!
- Generally, simplicity is preferred to complexity as well. A smaller, specialized model which is accessible to train and/or fine tune can provide more value than a larger, untrainable model which is not specialized. Additionally, the specialized nature of the smaller model can help ensure that there is less of a likelihood for undesired behaviors.
For these reasons, we believe that the DLite family remains highly relevant to modern large language model use cases, particularly when resources are highly constrained and/or the specialization of the LLM is highly important.
Training DLite Yourself
For those who want to train their own versions of DLite (V1 or V2), we have completely open sourced the training code on our GitHub repository as well! By default, the notebook in the repository will train the 124 million parameter version of DLite V2. To train DLite V1, simply change the dataset to the alpaca dataset. To train a different base model (by default, we use the smallest version of GPT2), simply change the `model_id` parameter in the notebook. It’s really that simple!
Because tuning models in the DLite family is so cost-efficient and fast, they are ideal candidates to tune to specific use cases. This opens the door for organizations to create a specialized model using their own data, ensuring that data remains private and doesn’t need to be shared with any 3rd party. To tune a DLite model for a use case, we’ve settled on a two-step procedure:
- Training the model on domain — specific data
- Train the model on relevant question — answer pairs
The initial training allows the model to learn the domain — specific terminology. As an added bonus, this step is fairly simple as it doesn’t require human annotation! The second step helps to reinforce the chatbot behavior of a DLite model while simultaneously tuning the model to become a specialized agent. Based on your requirements, you can choose to use human — annotated or AI — generated question — answer pairs. This is the exact procedure we used to train a fun example of a DLite model that acted as a question — answering ‘expert’ about the 2023 Databricks Data and AI Summit this past June in San Francisco. You can see this fine — tuned DLite on Huggingface, and our training script for this use case is on Github.
We are also excited to announce that our training code leverages the new capabilities of MLFlow 2.3.0 to log the trained model as well as training parameters such as the base model, the training dataset, and the number of epochs. These new capabilities from the MLFlow team have been integral to our development and experimentation processes, as they have enabled us to streamline our model versioning and evaluation processes. The final cell of the training notebook performs those operations.
What’s Next for AI Squared?
AI Squared is excited to continue its research and development of tools to leverage large language models easily, effectively, and economically. Our current research focus is split between two complementary lines of work. First, we are exploring model and tool chaining paradigms such as Langchain, and evaluating the suitability of smaller models, such as quantized LLMs and specifically-trained DLite models, to act as agents and tools within Langchain. Second, we are looking into how AI Squared and MLflow can be used to monitor the behavior of, and progressively improve, Langchain-style systems through the aggregation of user feedback and other relevant metrics of system performance, and then automatically retraining and re-deploying elements of the chain.
We would be thrilled to share with you what we’ve built so far, and our ongoing progress! To learn more and follow along, visit our website and Hugging Face page, where you can see examples of our DLite series as well as get a sense of how customers are applying DLite to real-world use cases.