Improving Decision Making with Intelligent Applications
Making ML outputs actionable, accurate, and relevant for end users

By Ian Sotnek @ AI Squared
Introduction
In a business context, the application of machine learning can be broken down into two broad categories. The first of these is the complete automation of a system by directly replacing the human in the loop — an example of this is the chatbots which are increasingly seen embedded in websites. The second category serves to support the human-in-the-loop rather than replace them, in effect using the automated system to augment or extend the cognition of the human end user to boost efficiency, efficacy, or both. For cases in the second “teaming” category, the way that this human-machine teaming paradigm is constructed is consequential — one does not simply train a model, deploy it to a serving platform, and hope for the best to empower end users! In fact, the best examples of empowering end users tend to involve a minimum of direct interaction between the end user and the machine learning model.
The “Deploy and Pray” Model
So, how do organizations empower their employees with machine learning? One option is to completely disregard the end-user experience and make the model available behind some endpoint where the user can directly query the model. This is, of course, technically complex and not entirely intuitive. For example, a user within their workflow identifies a gap in their knowledge that can be addressed with an available machine learning model, determines what information will adequately allow the model to fill that knowledge gap, and then selects the correct input to pass into the model. Next, the user exits their workflow to e.g. a command-line interface, Jupyter notebook, etc. to make a call to the deployed model, receives a JSON output from the model endpoint, parses the model output to determine the answer to their original question, and then returns to their original workflow armed with the model output. This workflow is illustrated in Figure 1.
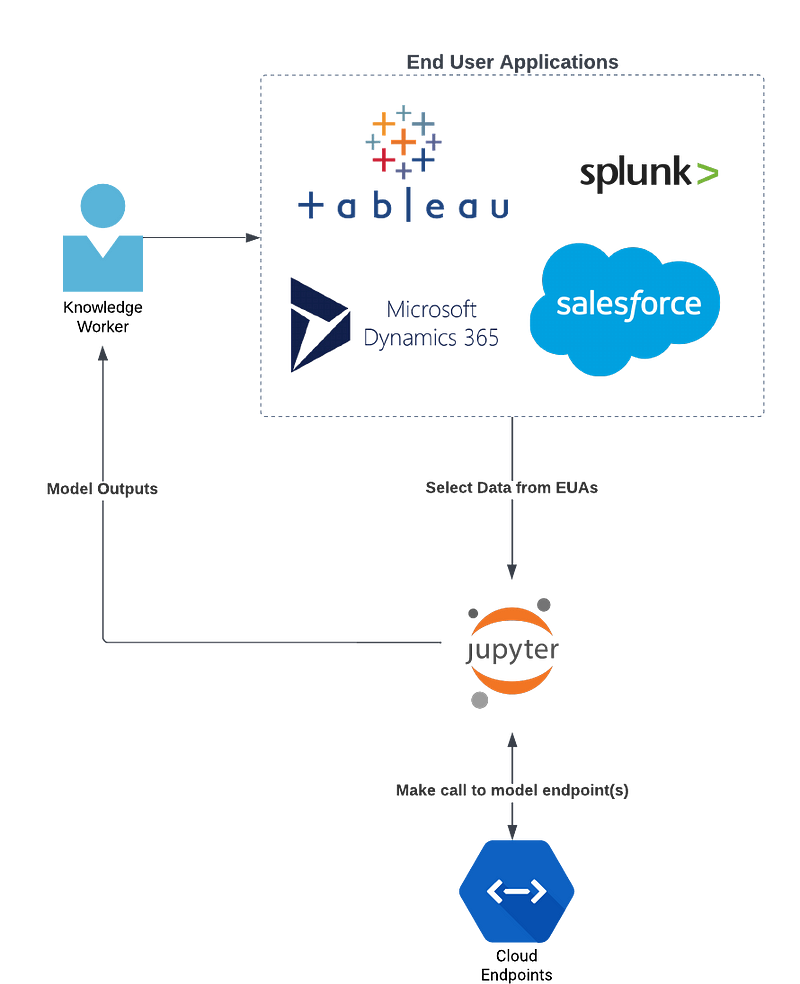
As illustrated by Figure 1, this both difficult and disruptive — the technical hurdles are far from insurmountable, but they are still adding complexity to the end-user’s workflow, in effect adding a barrier to the usage of the model itself — every time the end user identifies a gap in their knowledge, they will be asking themselves whether the time and energy required to leverage a machine learning model is greater than the value of the model’s results itself.
Standalone Applications and Embedded Dashboards
To make model results more accessible and easier to work with, an approach organizations often take is to wrap a model in a stand-alone application. Functionally, this looks like a much more user-friendly experience, and for the most part it is. Users benefit from the use of input fields to receive and perhaps even preprocess user-generated inputs, the process of making a call to the model endpoint is automated, and the advanced data visualization capabilities make understanding the model outputs much more accessible. This workflow is illustrated in Figure 2.
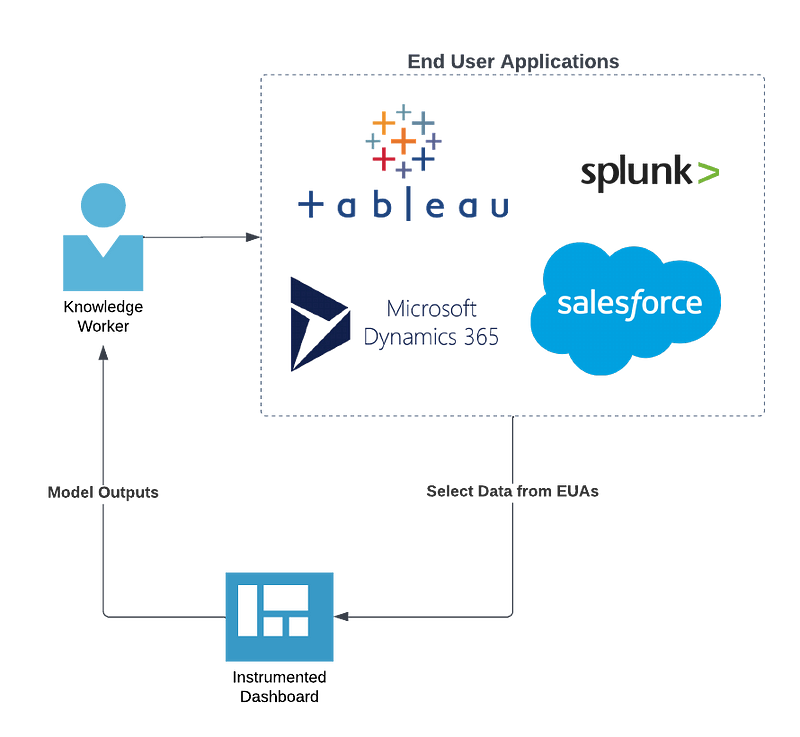
Unfortunately, this is not a perfect solution — in the paradigm depicted in Figure 2, an organization is required to invest in not only training a model but also developing, hosting, and managing an entire application. This can represent a huge time and financial commitment, to say nothing of the loss in organizational momentum around a machine learning project. As with other software development initiatives, machine learning benefits from an agile approach, wherein a model is created, tested, deployed to production, assessed in production, and retrained to account for issues caught in the ongoing assessment process. This can be effectively kneecapped by a slow application development process following the creation of a machine learning model — if the data domain the model is expected to predict on shifts while the application is in development, that model has essentially gone stale on the shelf.
The use of standalone applications, which frequently take the form of machine learning-embedded dashboards, is also not ideal from an organizational or user workflow perspective due to the inefficiencies inherent in scaling this approach. Business users might use a handful of SaaS applications in their typical workflow (e.g. Salesforce, Microsoft Dynamics, Splunk, etc.), but there could be hundreds of opportunities for knowledge gaps to appear that could be remedied by machine learning, with each knowledge gap potentially necessitating one or more models, requiring one or more inputs, and returning one or more outputs. As a single dashboard would quickly become unwieldy, organizations employing this approach can quickly wind up supporting a vast constellation of expensive internally developed standalone applications to serve their user base. Despite the user experience improvements with this approach, the end user is still required to step out of their preferred workflows to utilize machine learning. This still introduces some friction into the workflow of the end user, requiring them to step out of their business SaaS applications and disrupting their flow. This approach also asks the end user to consider the output of the machine learning models in isolation of the data the model is deriving its insights from, eliminating the context the model’s results are based on and eroding the component of trust in the human-machine team.
Intelligent Applications
AI Squared established that utilizing machine learning should augment the end user while causing minimal disruption to their workflow, while at the same time, minimizing the complexity and cost of scaling many models across an organization. An alternative approach to utilizing machine learning is available, however: transforming the tools that end users are already using within their workflow into “Intelligent Applications”. Intelligent Applications are more than just a new spin on dashboards: what they entail is the embedding of machine learning results into or onto an end-user application (e.g. Salesforce), enabling the model to provide the end user with accurate, relevant, and actionable information when, where, and how it can augment human decision making. The paradigm of teaming humans with intelligent applications is illustrated in Figure 3.
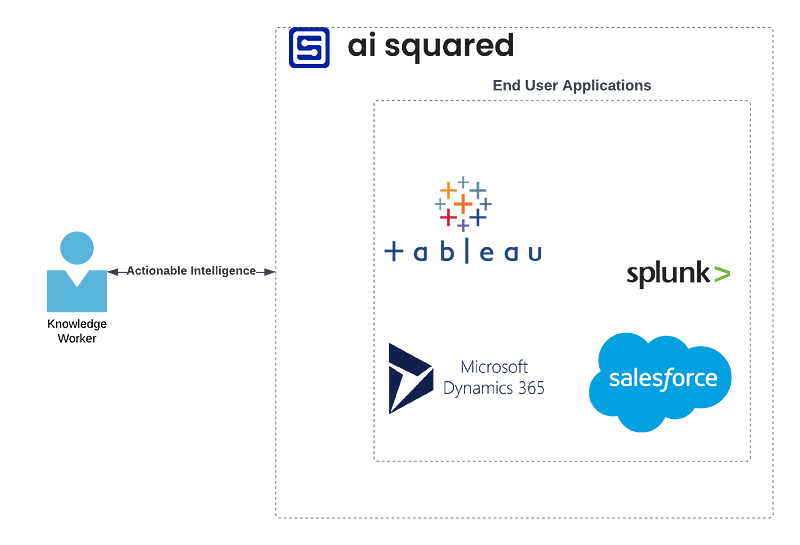
By embedding machine learning into existing applications rather than building bespoke applications or instrumented dashboards, the amount of time taken to get a model from a data science team to end users becomes decoupled from the inefficiencies of enterprise IT and internal development efforts, meaning that models can be requested, developed, and put into production with agility and velocity. This also means that model results will appear in the context of other relevant information, aiding the end user in interpreting the value and accuracy of the model’s outputs. This facilitates something new in human-machine teaming: intelligence coming full-circle. By considering the model’s outputs alongside other relevant data points, as well as in the context of their workflows, end users can develop a clear image of both the model’s performance (i.e. the accuracy of the model’s outputs on an output-by-output basis) and the model’s applicability (i.e. the degree to which a model is providing information that is useful in the context of the end-user’s workflow). Taken together, these data points can be invaluable for organizations interested in rapidly prototyping, evaluating, and iterating on their models in production, as well as evaluating the return on their investment in the machine learning capabilities they have developed to support their workers.
Conclusion
It’s easy to expect that some business value will follow from building a machine learning model and making it available to end users to extend or enhance their cognition. What we have seen, however, is that careful consideration should be taken in determining how machine learning can be effectively utilized to augment end users without introducing additional workflow frictions or technical hurdles which can serve as barriers to the adoption of the machine learning models the organization has invested in.
“Intelligent Applications” conjures images of Minority Report-style applications with hugely complex data visualizations, but the reality is both more realistic and, frankly, more useful. An Intelligent Application entails empowering end users with machine learning model outputs being made available when, where, and how they will be useful and effective at delivering accurate, relevant, and actionable insights — directly within the SaaS applications that end users are already using as the backbone of their workflows.