Reverse ETL 101

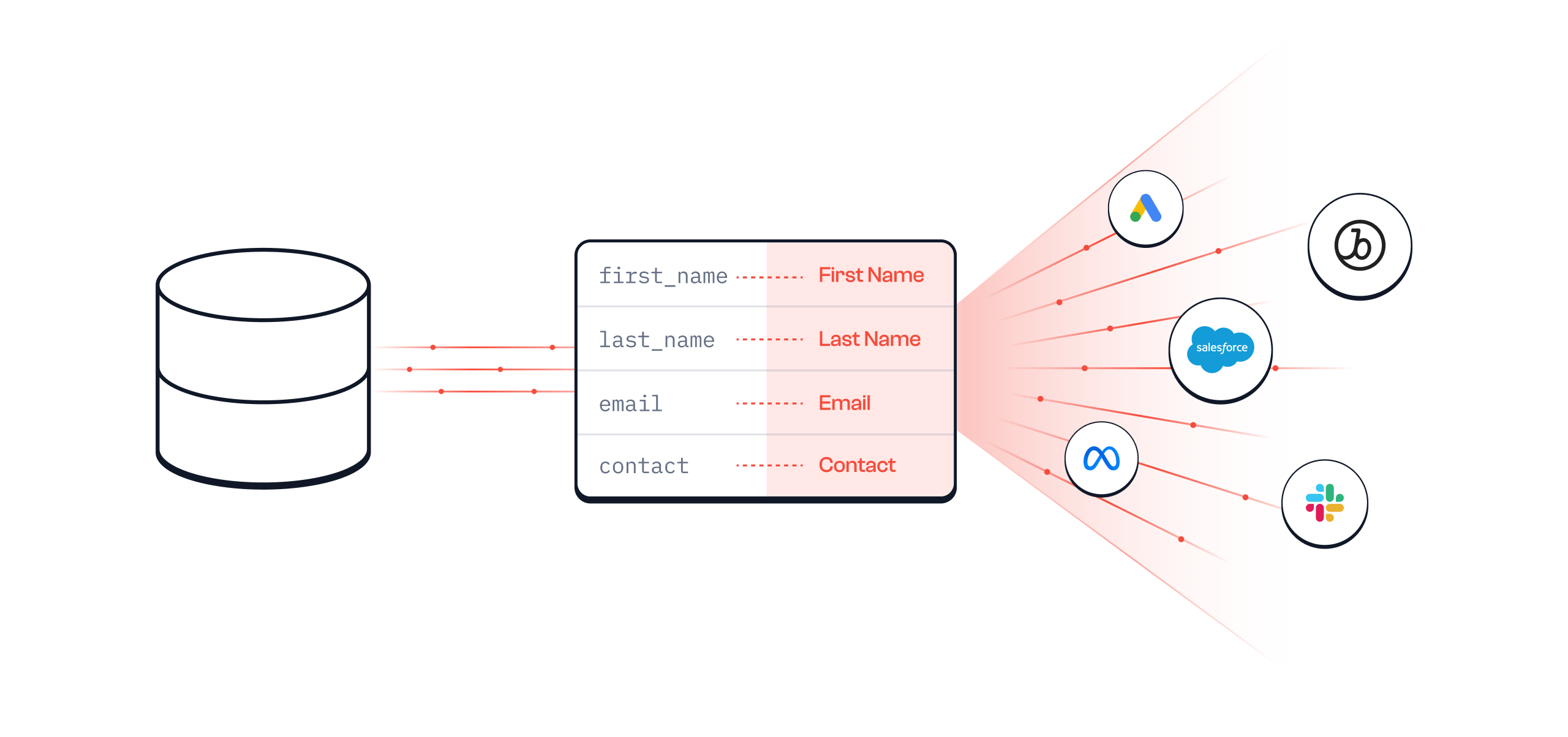
Rapidly growing silos of data
Businesses collect a large amount of data from various sources such as websites, mobile apps, physical points-of-sale and third-party tools.
This data typically resides in a data warehouse like Snowflake, Amazon Redshift, Databricks, Google BigQuery or PostgreSQL. However, this data is often underutilized as it's stuck in the data warehouse and not easily accessible to the teams that need it. For example, the Marketing team may want to use this data to create targeted campaigns in their marketing platforms, the Sales team may want to use it to engage with customers in their CRM software, and the Product team may want to use it to improve the user experience.
However, the data is often siloed in the warehouse and not easily accessible for "activation".
How can data be activated
Data in the warehouse can be used by different teams and tools, through:
- Manual exports: The data team can manually write SQL queries, export the data, and upload data files to the target systems. This approach is time-consuming, error-prone, and not scalable.
- Custom-built syncs: Data engineers are needed to build custom integrations and syncs- to move the data from the data warehouse to the target systems. This approach requires a deep understanding of the data warehouse, schema of the target systems, and individual APIs. Additionally, building custom syncs involves engineering complexity around building data pipelines, handling scale, rate-limiting, retries and more - to ensure that the data is always up-to-date and accurate.
- Reverse ETL (rETL): ETL is a process that Extracts, Transforms and Loads from multiple sources to a destination data warehouse. Deploying a Reverse ETL (or rETL) solution automates the process of moving data from the data warehouse to various destinations such as CRM software, marketing tools, and advertising platforms. Reverse ETL solutions are designed to be self-service and enable teams to build and maintain syncs with the tools and applications they use daily - reducing engineering overhead and enabling teams to move faster.
What exactly is Reverse ETL?
Reverse ETL (rETL) takes the organized data from the data warehouse and moves it into apps and tools businesses use daily, such as Sales, Marketing and Advertising platforms.
How Does Reverse ETL Work?
Reverse ETL works by running a series of queries on the data warehouse to extract the relevant data and then transforming it into a format that the target systems can ingest. The transformed data is then loaded into the target systems using their respective APIs.
Any changes in the data warehouse are automatically detected and synced with the target systems, ensuring that the data is always up-to-date and accurate. This process is usually referred to as Change Data Capture (CDC).
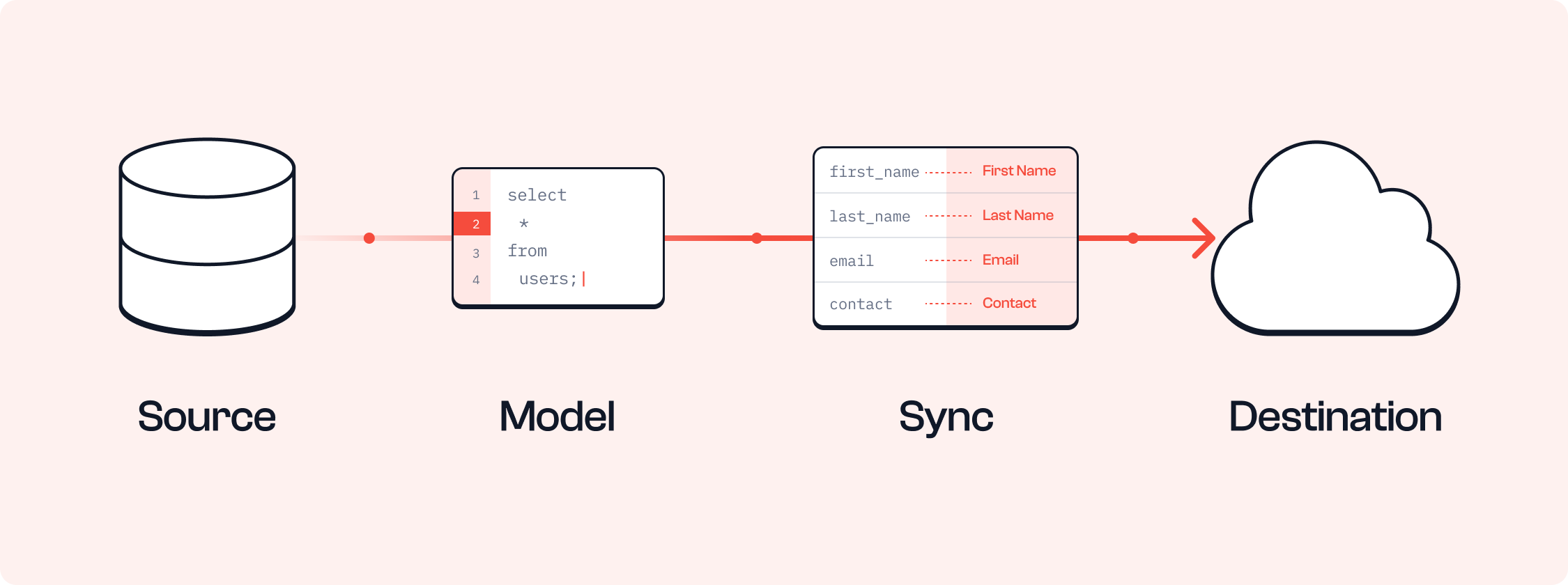
There are four main components of a Reverse ETL solution:
- Sources: The data warehouse. This could be Snowflake, Redshift, Databricks, Google BigQuery or any data repository.
- Models: The data models that define the structure of the data in the data warehouse(s). These could be tables, views, or materialized views. Models can be defined using one of the following approaches:
- SQL: You can write SQL queries to extract the relevant data from the data warehouse and transform it into a format that the target systems can ingest. This approach is flexible and allows you to define complex transformations using SQL.
- dbt: You can use dbt to define the transformations that need to be applied to the data in the data warehouse. dbt is a popular open-source tool that allows you to define data models using SQL and then run these models to transform the data in the warehouse.
- Visual: You can use a visual interface to define the transformations that need to be applied to the data in the data warehouse. This approach is user-friendly and allows you to define transformations using a drag-and-drop interface.
- Syncs: The process of moving data from the data warehouse to the target systems. Syncs are typically defined using a configuration that specifies the interval at which the data is synced, whether the sync is incremental or full, and the transformations that need to be applied to the data.
- Destinations: The target systems where the data is loaded. These could be CRM software, Marketing platforms, Advertising platforms, etc.
Why is Reverse ETL important?
Let's run through a few use-use cases to understand how Reverse ETL can be used
1. Marketing:
Imagine a business that has collected a large amount of customer data in their data warehouse..
This data typically includes information about customer interactions, purchase history, and other relevant details. This could also include modeled data generated by data science teams.
Now the marketer wants to use this data to create targeted campaigns in one of their marketing platforms like Braze or Klaviyo, but the data is stuck in the warehouse. The data teams usually have to manually write SQL queries, export the data and upload it to the marketing platform, which is time-consuming and error-prone. With Reverse ETL, the data can be automatically synced with the marketing platform, ensuring that the marketing team has access to the most recent and relevant data for their marketing campaigns.
2. Sales:
Sales teams often use CRM software like Salesforce or HubSpot to manage customer relationships and track sales activities.
Imagine a scenario where a customer visits the website and interacts with the business, but the sales team doesn't have access to this information in their CRM system. Using a Reverse ETL solution, the customer interaction data can be automatically synced with the CRM software, ensuring that the Sales team has access to the most recent and relevant data to engage with the customer effectively. Or a notification can even be sent to the Sales rep on Slack.
3. Ads:
Businesses often use advertising platforms like Facebook Ads or Google Ads to run targeted ad campaigns.
These platforms require data about customer interactions, purchase history, and other relevant details to create audiences in ad platforms to either serve specific audiences or create lookalikes. With Reverse ETL, the data can be automatically synced with the advertising platforms, ensuring that the marketing team has access to the most recent and relevant data to create targeted ad campaigns.

Should I Build or Buy a Reverse ETL Solution?
If you decide to build a Reverse ETL solution in-house, consider:
Engineering bandwidth and expertise: Building a Reverse ETL solution in-house requires a deep understanding of the data warehouse, the target systems, and the APIs of these systems. Additionally, building a Reverse ETL solution requires ongoing maintenance and support to ensure that the data is always up-to-date and accurate.
TCO (Total Cost of Ownership): Building a Reverse ETL solution in-house can be a time-consuming and resource-intensive process.
If you decide to buy a Reverse ETL solution, your options are:
Commercial SaaS offerings: There are several commercial SaaS Reverse ETL solutions available in the market, such as Hightouch, Census, and Segment. These solutions are designed to be self-service and enable teams to build and maintain syncs with the tools and applications they use daily.
Open-source offering: Teams that want to control their own customers' data by self-hosting might want to consider an open-source Reverse ETL solution such as Multiwoven. They are designed to be self-service and self-hosted on your infrastructure, thereby ensuring that your data is always secure and compliant with your organization's policies. Open-source rETL solutions are also ideal for teams that don't want large bills for moving data at scale.
Final Thoughts
In conclusion, Reverse ETL is a critical component of a modern data stack that enables businesses to unlock the value of their data by making it easily accessible to the teams that need it.
